
We spent over a decade standardising the Web of Things, but I believe it’s still missing a key component it needs in order to grow.
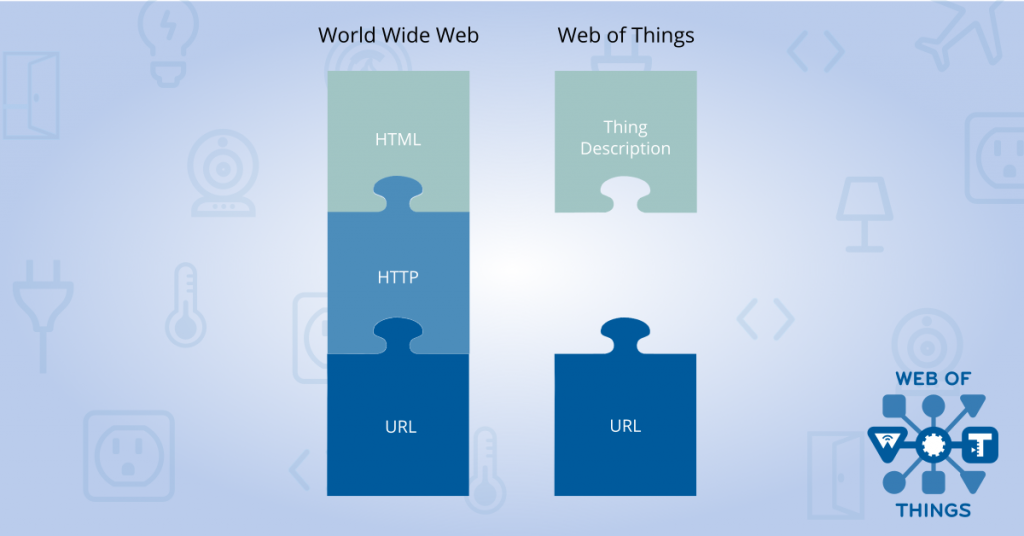
The Web of Things started with the simple but powerful idea of giving connected devices URLs on the web, to extend the World Wide Web of pages into a web of physical objects which can be monitored and controlled over the internet. The idea was to apply lessons learnt from the World Wide Web to the Internet of Things to create a unifying application layer that is to the Internet of Things what the World Wide Web is to the internet.
Over the last decade the W3C Web of Things Working Group has made great progress in standardising key building blocks for discovering and describing connected devices. However, when it comes to actually communicating with those devices we seem to have got stuck with just describing the fragmented landscape of IoT protocols that already existed, rather than defining something native to the web which truly has the potential to scale in the way the World Wide Web has.
In this blog post I will take a deep dive into the last 10+ years of Web of Things standardisation (from my own personal perspective), how we got where we are today, and why I believe the Web of Things is still missing an essential component due to a subtle misunderstanding about what makes the web the web.
Crucially, I explain how I think we can put the “web” back in the “Web of Things” with a universal web-based application layer protocol, to enable an open ecosystem of IoT web services which weave together the rich tapestry of the Internet of Things, rather than simply cementing the fragmentation that currently exists.
Table of Contents
- Beginnings
- WoT Community Group & Early Ideas
- Mozilla WebThings
- Standardising the Web of Things
- WoT Working Group
- The Web Thing Model and Mozilla’s Web Thing API
- Descriptive vs. Prescriptive: Two Schools of Thought
- Web Thing Protocol Community Group
- WoT Thing Description
- WoT Discovery & WoT Profile
- Binding Templates vs. Profiles: Two Sides Remain
- Bringing the Sides Together
- Changing of the Guard
- How is the Web of Things being used today?
- What is the narrow waist of the Web of Things?
- The Web Thing Protocol
- What’s Next?
- Call to Action
Beginnings
I first learnt about the “Web of Things” from a book by Dominique Guinard and Vlad Trifa called Building the Web of Things, published in 2016.

The book was based on the culmination of their learning from the Web of Things community they started in 2007 including an annual series of international workshops from 2010, with some early thinking the pair captured in a paper published in 2009, and Dominique’s PhD thesis in 2011. Dominique and Vlad went on to co-found EVRYTHNG Ltd., who developed what they described as the first commercial Web of Things platform.
I was inspired by the simple but powerful idea of giving connected devices URLs on the web to make them linkable and discoverable, and defining a standard data model and API to make them interoperable. The Web of Things would apply lessons learnt from the World Wide Web to the Internet of Things, in order to create a unifying application layer for the Internet of Things, linking together multiple underlying IoT protocols using existing web technologies.
“For the Internet of Things to become real, we need a single universal application layer protocol (think language) for devices and applications to talk to each other, regardless of how they’re physically connected. Rather than inventing yet another protocol from scratch (as many IoT projects have been – and keep – doing), why not reuse something that’s already widely used to build scalable and interactive applications, such as the web itself? This is what the Web of Things (and this book) is all about: using and reusing readily available and widely popular web protocols, standards, and blueprints to make data and services offered by Things more accessible to a larger pool of (web) developers.”
— Guinard & Trifa, Building the Web of Things, 2016
The book talks about three “integration patterns” for connecting IoT devices to the Web of Things:
- Direct – A Thing hosts an HTTP (REST and WebSocket) API directly
- Gateway – An on-premises application gateway translates non-Web and non-Internet protocols (e.g. MQTT and Zigbee respectively) to an HTTP API
- Cloud – A cloud service which acts as a gateway on a remote server to translate non-Web IoT protocols (e.g. MQTT) to an HTTP API
In all cases devices are ultimately exposed via HTTP REST and WebSocket APIs. Examples are given using the CoAP and MQTT protocols, but only in the context of the gateway and cloud integration patterns where a gateway and cloud service respectively are used to bridge these protocols to the web.
The book even goes as far as to say that if you can’t send an HTTP request to a device, then it’s not part of the Web of Things*:
Web Things must be an HTTP server. Simply put, if you can’t send an HTTP request to a device, then it’s not part of the Web of Things.
— Guinard & Trifa, Building the Web of Things, 2016
That doesn’t necessarily mean that every physical device has to talk HTTP directly, but that one way or another it must be possible to communicate with the web thing that represents it over the web. This was important because in order for the Web of Things to achieve the kind of scale that the World Wide Web has enjoyed, everyone needs to be talking the same language.
Just like the web has become the global integration platform for distributed applications over the internet, the Web of Things facilitates the integration of all sorts of devices and the applications that interact with them. In other words, by hiding the complexity and differences between various transport protocols used in the IoT, the Web of Things allows developers to focus on the logic of their applications without having to bother about how this or that protocol or device actually works.
–Guinard & Trifa, Building the Web of Things, 2016
* I’m not sure I would go quite as far as to restrict this to only HTTP, because I think we need to allow some room for innovation in web protocols. For example, CoAP is a very web-like protocol (kind of a mini HTTP) which can operate in very constrained environments where HTTP can’t, and adds the ability to observe resources. The important point is that the intention was for all web things to be communicated with via the web, not just described by the web, (i.e. a Web of Things, not a Web about Things).
WoT Community Group & Early Ideas
By the time Building the Web of Things was published, there was already a W3C Working Group doing early work to standardise the Web of Things. It had started with the creation of the WoT Community Group by Dave Raggett back in 2013, which led to the first W3C WoT Workshop in Berlin in 2014 where over 100 participants shared their early ideas.
The position papers submitted for the first W3C WoT Workshop in Berlin in 2014 make for very interesting reading. The paper that Dave Raggett himself put forward starts very clearly by saying:
This paper presents an architecture for a scalable services platform for the Web of Things with APIs for services layered on top of HTTP and Representational State Transfer (REST).
Raggett, An architecture for the Web of Things, 2004
I would also highlight (because it becomes important later on), that at the time of this workshop that also very much seemed to be the consensus of the workshop hosts, Siemens:
Web Architecture provides a general-purpose way of establishing an interlinked network of resources, which are interacted with through the exchange of representations of their state. We argue that the “Web of Things” fits well into this general framework, and thus should be built firmly on the foundation provided by Web Architecture…
For the “Web of Things” to become a global reality, there needs to be an open, modular, extensible, and flexible set of technologies that are in line with the Architecture of the World Wide Web, and can be used as a platform to build on. As a result, this platform should be a RESTful SOA…
–Wilde, Michahelles and L¨uder, Leveraging the Web Platform for the Web of Things: Position Paper for W3C Workshop on the Web of Things, 2014
Siemens actually suggested Activity Streams as one potential way that “streams of resource updates could be represented in a uniform, extensible, and machine-readable way”, and talked about “prescribed design patterns” or maybe “additional specifications to help increase interoperability”. They also said that “what matters is identification and interaction, but only via a representation (a.k.a. REST)”.
I recently used a Large Language Model to help analyse all 68 position papers from that workshop (one of the things that LLMs are actually very useful for, shout out to the Dia web browser which is very useful for this kind of thing). This revealed that based on those submissions the overwhelming consensus is that “things” are web resources with URIs, manipulated through a REST interface over HTTP/CoAP, described with common web data formats. They treat the web (HTTP/REST/URIs/Linked data) as the native application layer for the Web of Things, often extended with CoAP for constrained devices. They see existing IoT protocols (MQTT, Modbus, BACnet, OPC-UA, Zigbee etc.) as technologies to be wrapped, bridged or mapped into this web model, not as the primary “surface” of the Web of Things.
There is definitely a strong desire for a shared information model from semantic web/linked data folks, with common ontologies and a way to describe things and their capabilities. But this semantic layer is much more diverse (multiple ontologies, domain-specific models), often very domain-driven, and explicitly something that will evolve and be extended, not frozen as a tiny stable core.
Some of the browser folks also talk about a unified programming model (e.g. a uniform JavaScript API for both HTTP and CoAP requests). However, these APIs are seen as sitting on top of the REST/URI interface, not instead of it.
Ultimately what these papers really describe as the “narrow waist” of the Web of Things is:
- Resources with URIs
- RESTful methods (GET/PUT/POST/DELETE plus Observe/notify)
- HTTP or CoAP as the protocol surface
- A small set of web media types (JSON/CBOR, RDF/JSON-LD/Turtle)
… with information models and scripting APIs layered on top of that.
The reason I say all of this is to eventually contrast the clear early consensus about what the Web of Things should be, with what the current set of W3C WoT standards actually defines.
Shortly after the workshop in Berlin the WoT Interest Group was created at TPAC 2014 to start identifying use cases and requirements.
Mozilla WebThings
The book Building the Web of Things was what inspired me to start “Project Things” in the Emerging Technologies department at Mozilla, which was started in early 2017, announced in June 2017, became the Mozilla WebThings IoT platform in 2019, and would later be spun out as the independent WebThings open source project in 2020.
At Mozilla we observed that the Internet of Things at the time was mostly built on proprietary vertical technology stacks, each dependent on a central point of control, which didn’t always talk to each other, and when they did it required per-vendor integrations. Driven by Mozilla’s mission to “to ensure the Internet is a global public resource, open and accessible to all”, we saw the Web of Things as a potential solution to this problem.
Having read Building the Web of Things I eagerly shared the vision of the Web of Things with leaders at Mozilla as being a very Mozilla-like approach to the Internet of Things. I pitched the idea of “Mozilla WebThings” as an IoT platform developed by Mozilla, taking the form of an open source implementation of the Web of Things, providing a unifying horizontal application layer for the Internet of Things.
Inspired by the three integration patterns from the book, the three main components would be a gateway, a cloud service and framework for developing native web things. A few months later, Mozilla announced what was initially called “Project Things” (to emphasise its experimental status).
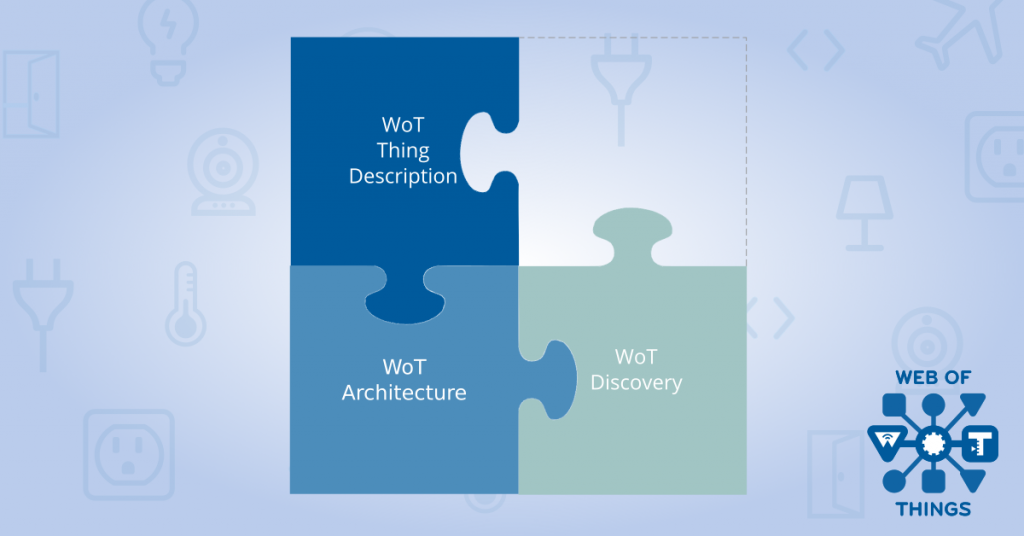
Standardising the Web of Things
WoT Working Group
By December 2016 the WoT Working Group had already started work on writing the first normative specifications – WoT Thing Description and WoT Architecture.
The Mozilla IoT team were clear that we didn’t want Project Things to create another proprietary vertical technology stack, we wanted to participate in the existing Web of Things community and make the Web of Things the platform. Mozilla WebThings was intended to be one open source implementation of a Web of Things standard, in the same way that Firefox is one implementation a web user agent and Apache is one implementation of a web server.
I had therefore been keeping a close eye on the W3C’s standardisation work and had managed to convince Mozilla’s W3C representatives (they did require some convincing) that Mozilla should join the WoT Interest Group. However, Mozilla initially declined to join the WoT Working Group because they disagreed about some parts of the first charter. They had made formal objections which were not addressed, so they decided not to join. Mozilla’s reservations (some coming from the Mozilla’s platform team and some coming from the Mozilla IoT team) were:
- They thought several of the proposed deliverables lacked sufficient incubation to be placed on the W3C Recommendation track.
- They thought the charter had an overly broad scope and should first focus on defining a core Thing Description format rather than pursuing a wide range of other deliverables.
- They were concerned about the dependency on semantic web technologies like RDF and JSON-LD and felt the default representation format for Thing Descriptions should be plain JSON (RDF was very unpopular at Mozilla at the time because of a bad experience of trying to use RDF in XUL as part of the architecture of Firefox).
- They thought that defining declarative “protocol bindings” using “binding templates” and “hypermedia forms” was unnecessarily complicated, and favoured a prescriptive HTTP API and simple hyperlinks instead.
- They thought the architecture document should be an informative note rather than another normative specification.
- They didn’t support the Scripting API specification (which didn’t have the support of any other browser vendors either).
- They expressed concerns over privacy and security.
The Web Thing Model and Mozilla’s Web Thing API
The book Building the Web of Things had introduced a proposal called the “Web Thing Model” (a formal W3C member submission) which defines an HTTP REST & WebSocket API for retrieving metadata about a Thing, and communicating with it. This included a root JSON resource which was an early version of a Thing Description containing top level metadata about the Thing, then a fixed URL structure for interaction with “properties” and “actions” using HTTP GET and POST. The Mozilla IoT team saw this as a simpler, more pragmatic approach.

So instead of jumping straight into implementing the W3C’s nascent work on Thing Descriptions, the Mozilla IoT team took the Web Thing Model as a starting point and designed our own Web Thing API which took what we considered to be a more pragmatic approach, with plain JSON Thing Descriptions and simple hyperlinks rather than JSON-LD and “hypermedia forms”. Our early single specification defined a plain JSON Web Thing Description format for describing Things, a prescriptive Web Thing REST API (with URLs provided in Thing Descriptions rather than using a fixed URL structure) which could be used for communicating with Things using HTTP, and a Web Thing WebSockets API for push notifications and real-time communication.

Looking to build consensus around this approach I met Dominique and Vlad at the EVRYTHNG headquarters in London in October 2017 to work towards a joint member submission to the W3C, which combined their early work on the Web Thing Model with an early version of Mozilla’s Web Thing API specification.

We came up with a joint proposal from Mozilla, EVRYTHNG and Ambrosus Technologies for a plain JSON Web Thing Description format which could be parsed as plain JSON, with optional semantic annotations using JSON-LD. We also still favoured “links” over “forms”.

We shared this proposal as members of the Interest Group (though weren’t allowed to call it a member submission), and the ensuing discussion in the Working Group eventually resulted in some simplifications to the nascent Thing Description specification.
The Working Group agreed that the default representation format should be plain JSON (with optional JSON-LD style semantic annotations), but we lost the argument about “links” vs. “forms”.
Descriptive vs. Prescriptive: Two Schools of Thought
Overall we felt that the Thing Description specification was now going in a better direction, which would enable us to standardise the Web Thing Description part of Mozilla’s Web Thing API specification, but the REST & WebSockets APIs were still specific to Mozilla WebThings.
In the 1.0 family of specifications the Working Group had decided to define something which was entirely programming language agnostic, protocol agnostic, and content type agnostic in order to be as extensible and flexible as possible. They had decided (contrary to the early consensus about a largely HTTP-based REST style architecture) that Thing Descriptions should be able to describe any existing IoT protocol through an extensible system of declarative “protocol bindings”, serialised as “hypermedia forms”.
“Binding templates” would define a semantic vocabulary for binding a fixed set of WoT operations like “readproperty”, “invokeaction” and “subscribeevent” to concrete messages in a given protocol. So for example, the HTTP vocabulary would enable a Thing Description author to say that if a Consumer wants to read a property they should send an HTTP GET request to a certain URL with certain HTTP headers set, and should expect a certain response code in response.
Rather than a prescribing a concrete REST & WebSockets API like those proposed in the Web Thing Model and Mozilla’s Web Thing API, this declarative approach would theoretically be able to describe any REST API, even existing proprietary ones. If it had stopped there, I think that would almost have been OK. But the concept of protocol bindings was also then extended to describing any protocol and data format, even non-web ones which were not inherently resource oriented (e.g. MQTT, Modbus, BACnet and OPC-UA). The only requirement (which we had to fight for) was that the protocol would have to have a URI scheme and the data format would have to have a MIME type in order to be described in forms.
Rather than providing a universal web-based application layer protocol for the Internet of Things, the Web of Things would therefore provide metadata that described how to communicate using existing IoT protocols. Many members of the Working Group were worried that if we tried to define anything that looked like a new protocol, the Web of Things would be seen as just another IoT protocol that added to the problem, rather than a solution to the fragmentation. The infamous XKCD 927 comic strip was often referenced when trying to justify this direction.

Whilst that comic strip is quite funny and makes a valid point about standards, I also think it was very unhelpful in this particular instance. Our argument was never that HTTP was the best IoT protocol (it definitely isn’t) and should replace all other IoT protocols (it definitely shouldn’t). It was that due its simplicity and ubiquity, an HTTP-based application layer protocol could help provide a universal web abstraction on top of other IoT protocols that an open ecosystem of apps and services could then consume.
The irony of the xkcd argument is that the exact same comic strip is printed in the book Building the Web of Things to justify defining a prescriptive universal application layer protocol built on HTTP, rather than re-inventing the wheel. I think the fact that the same image was used to argue opposite sides of the argument shows just how nonsensical it was.
Whilst very flexible, the downside of all the open ended extensibility of “binding templates” was that it was now effectively impossible to build a single WoT Consumer which was guaranteed to be able to communicate with any Web Thing, in the way that any web browser can render just about any web page. Whilst Thing Descriptions provided a common metadata format, Consumers ultimately still had to implement each individual IoT protocol in order to communicate with different devices.
The Mozilla IoT team still believed the Web of Things needed a more prescriptive universal application layer protocol, so I started to seek support for a separate community group to explore that direction further.
Web Thing Protocol Community Group
After defining a proposed scope and gathering enough initial supporters, in September 2019 I launched the Web Thing Protocol Community Group to “define a common protocol for communicating with connected devices over the web, to enable ad-hoc interoperability on the Web of Things.”
The deliverables defined in the group charter included:
- Definition of a WebSocket sub-protocol for the Web of Things, using the W3C “Web of Things (WoT) Thing Description” data model and operations
- Definition of an HTTP sub-protocol for the Web of Things
(or support of the Web of Things Working Group in defining this sub-protocol and ensuring consistency with the WebSocket sub-protocol where appropriate)- Evaluation of other potential Web of Things sub-protocols (e.g. for CoAP)
We hoped that the Working Group would eventually come around to defining a prescriptive HTTP protocol binding. There was general agreement that a WebSocket sub-protocol was needed, but the WoT Working Group felt it needed incubating somewhere before joining a standards track, so they were at least happy for the community group to be spun off to work on that.
The community group started work on a Use Cases & Requirements report which outlined requirements for both an HTTP and WebSocket sub-protocol.

WoT Thing Description
The first formal W3C WoT Recommendations were published in April 2020:
- Web of Things (WoT) Architecture 1.0 – Described the building blocks of the Web of Things and how they fitted together (and did end up being a separate normative specification).
- Web of Things (WoT) Thing Description 1.0 – Defined an information model and representation format for describing the metadata and interfaces of “things” (including a default JSON representation, but “forms” in addition to “links”)


This was a promising starting point, but Mozilla didn’t immediately implement the W3C WoT specifications in WebThings. Instead we continued to implement an evolved version of the Web Thing API which was a little closer to the W3C specifications (e.g. used a very similar information model with properties, actions and events, and allowed semantic annotations for describing capability schemas) but still used links rather than forms.
It was around this time that Mozilla also laid off the entire Emerging Technologies department that built the WebThings platform, and some ex-colleagues and I spun WebThings out of Mozilla as an independent open source project.
In December 2020 I set out a vision for the future of the now community-run WebThings platform under the new stewardship of my startup, Krellian. One of the items in that roadmap was compliance with the newly published W3C WoT standards, using the proposed Web Thing Protocol to fill the gaps I perceived existed in the W3C specifications.
WoT Discovery & WoT Profile
Meanwhile, after multiple extensions, a new charter for the WoT Working Group had been published in January 2020 which added new normative deliverables for the Working Group:
- The Web of Things (WoT) Discovery specification would focus on how Thing Descriptions are discovered, including the definition of various discovery mechanisms and the Directory Service API.
- The Web of Things (WoT) Profile specification would define “profiles for subsets of TDs to enable plug-and-play interoperability.”
(Still suffering from a lack of consensus the Scripting API also became an informative rather than normative deliverable, but it would still stick around as a Working Group Note).
I supported the work on both of the new normative deliverables.
The WoT Discovery specification included the definition of a prescriptive HTTP REST API called the Directory Service API for managing a directory of Thing Descriptions (which was similar to the “Things” resource in Mozilla’s Web Thing API specification), and standardised DNS-based discovery of Things using mDNS/DNS-SD (which was also something we had defined in Mozilla’s Web Thing API specification).
The WoT Profile specification was originally proposed by Oracle as a way of improving interoperability on the Web of Things. Profiles would ensure that any WoT Consumer conforming to a profile would be able to communicate with any Thing also conforming to that profile, by limiting complexity and constraining the extension points in Thing Descriptions to a finite set of options.
When I heard about Profiles I jumped on the idea because it sounded like a potential way to achieve the kind of universal application layer we had set out to define in the first place. By constraining Things to a finite set of prescriptive protocol bindings and payload formats, and constraining other extension points, we could offer a prescriptive approach to using the Web of Things which implementations could opt-in to using in order to benefit from more interoperability guarantees.
Unfortunately it didn’t go very well.
From the beginning there were disagreements over what Profiles should and shouldn’t define. On the one hand early drafts of profiles tried to constrain the sizes of strings and data structures in Thing Descriptions to optimise for constrained devices, but on the other hand made more of the members of a Thing Description mandatory in order to optimise for human readability, and even extended its ontology to describe concepts that couldn’t otherwise be described. There were disagreements over whether there should be profiles for specific application domains, or whether they should be domain agnostic, and whether specific ontologies should be required for describing units.
Profiles tried to prescribe fixed protocol bindings in order to enable out-of-the-box interoperability, but when it was found that the APIs for some operations were not possible to fully describe using declarative protocol bindings, they ended up defining APIs that Thing Descriptions alone would not be able to describe. There were disagreements over which eventing mechanisms to use in the protocol bindings, and whether to re-use existing de-facto standards for event payloads or invent new approaches that were tailored to the Web of Things information model.
By the time WoT Architecture 1.1, Thing Description 1.1 and WoT Discovery 1.0 were published as W3C Recommendations in December 2023, the WoT Profile specification was still stuck at the draft stage.

Binding Templates vs. Profiles: Two Sides Remain
Once the dust had settled, we arrived at a Working Draft of the WoT Profile specification in 2023 which defined a set of common constraints around accessibility, units, date format, security, discovery and links, and then three initial domain-agnostic profiles – the HTTP Basic Profile, HTTP SSE Profile and HTTP Webhook Profile.

These profiles make it possible to drastically reduce the complexity of Thing Descriptions and Consumer implementations. For example, below is the Thing Description for a simple web thing representing a connected lamp when using the HTTP Basic and HTTP SSE profiles:
{
"@context": "https://www.w3.org/2022/wot/td/v1.1",
"id": "https://mywebthingserver.com/things/lamp",
"profile": [
"https://www.w3.org/2022/wot/profile/http-basic/v1",
"https://www.w3.org/2022/wot/profile/http-sse/v1"
],
"base": "https://mywebthingserver.com/things/lamp/",
"title": "My Lamp",
"description": "A web connected lamp",
"securityDefinitions": {
"oauth2": {
"scheme": "oauth2",
"flow": "code",
"authorization": "https://mywebthingserver.com/oauth/authorize",
"token": "https://mywebthingserver.com/oauth/token"
}
},
"security": "oauth2",
"properties": {
"on": {
"type": "boolean",
"title": "On/Off",
"description": "Whether the lamp is turned on",
"forms": [
{
"href": "properties/on"
},
{
"href": "properties/on",
"op": ["observeproperty", "unobserveproperty"],
"subprotocol": "sse"
}
]
},
"level" : {
"type": "integer",
"title": "Brightness",
"description": "The level of light from 0-100",
"unit": "percent",
"minimum" : 0,
"maximum" : 100,
"forms": [
{
"href": "properties/level"
},
{
"href": "properties/level",
"op": ["observeproperty", "unobserveproperty"],
"subprotocol": "sse"
}
]
}
},
"actions": {
"fade": {
"title": "Fade",
"description": "Fade the lamp to a given level",
"synchronous": false,
"input": {
"type": "object",
"properties": {
"level": {
"title": "Brightness",
"type": "integer",
"minimum": 0,
"maximum": 100,
"unit": "percent"
},
"duration": {
"title": "Duration",
"type": "integer",
"minimum": 0,
"unit": "milliseconds"
}
}
},
"forms": [{"href": "actions/fade"}]
}
},
"events": {
"overheated": {
"title": "Overheated",
"data": {
"type": "number",
"unit": "degree celsius"
},
"description": "The lamp has exceeded its safe operating temperature",
"forms": [{
"href": "events/overheated",
"subprotocol": "sse"
}]
}
},
"forms": [
{
"op": ["readallproperties", "writemultipleproperties"],
"href": "properties"
},
{
"op": ["observeallproperties", "unobserveallproperties"],
"href": "properties",
"subprotocol": "sse"
},
{
"op": "queryallactions",
"href": "actions"
},
{
"op": ["subscribeallevents", "unsubscribeallevents"],
"href": "events",
"subprotocol": "sse"
}
]
}Below is my best attempt at describing this same Web Thing without Profiles:
{
"@context": "https://www.w3.org/2022/wot/td/v1.1",
"id": "https://mywebthingserver.com/things/lamp",
"base": "https://mywebthingserver.com/things/lamp/",
"title": "My Lamp",
"description": "A web connected lamp",
"securityDefinitions": {
"oauth2": {
"scheme": "oauth2",
"flow": "code",
"authorization": "https://mywebthingserver.com/oauth/authorize",
"token": "https://mywebthingserver.com/oauth/token"
}
},
"schemaDefinitions": {
"error": {
"type": "object",
"properties": {
"type": {
"type": "string",
"format": "uri"
},
"title": {
"type": "string"
},
"status": {
"type": "number"
},
"detail": {
"type": "string"
},
"instance": {
"type": "string",
"format": "uri"
}
}
},
"actionStatuses": {
"type": "object",
"propertyNames": {
"type": "string"
},
"additionalProperties": {
"type": "array",
"items": {
"type": "object",
"properties": {
"state": {
"type": "string",
"emum": ["pending", "running", "completed", "failed"]
},
"output": {},
"error": {
"$ref": "#/schemaDefinitions/error"
},
"href": {
"type": "string",
"format": "uri"
},
"timeRequested": {
"type": "string",
"format": "date-time"
},
"timeEnded": {
"type": "string",
"format": "date-time"
}
}
}
}
}
},
"security": "oauth2",
"properties": {
"on": {
"type": "boolean",
"title": "On/Off",
"description": "Whether the lamp is turned on",
"forms": [
{
"href": "properties/on",
"op": "readproperty",
"response": {"htv:statusCodeNumber": 200},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "properties/on",
"op": "writeproperty",
"response": {"htv:statusCodeNumber": 204},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "properties/on",
"op": "observeproperty",
"htv:methodName": "GET",
"subprotocol": "sse",
"htv:headers": [
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Accept",
"htv:fieldValue": "text/event-stream"
},
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Connection",
"htv:fieldValue": "keep-alive"
}
],
"response": {
"htv:statusCodeNumber": 200,
"htv:headers": [
{
"@type": "htv:ResponseHeader",
"htv:fieldName": "Content-Type",
"htv:fieldValue": "text/event-stream"
}
]
},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "properties/on",
"op": "unobserveproperty",
"subprotocol": "sse"
}
]
},
"level" : {
"type": "integer",
"title": "Brightness",
"description": "The level of light from 0-100",
"unit": "percent",
"minimum" : 0,
"maximum" : 100,
"forms": [
{
"href": "properties/level",
"op": "readproperty",
"response": {"htv:statusCodeNumber": 200},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "properties/level",
"op": "writeproperty",
"response": {"htv:statusCodeNumber": 204},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "properties/level",
"op": "observeproperty",
"subprotocol": "sse",
"htv:methodName": "GET",
"htv:headers": [
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Accept",
"htv:fieldValue": "text/event-stream"
},
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Connection",
"htv:fieldValue": "keep-alive"
}
],
"response": {
"htv:statusCodeNumber": 200,
"htv:headers": [
{
"@type": "htv:ResponseHeader",
"htv:fieldName": "Content-Type",
"htv:fieldValue": "text/event-stream"
}
]
},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "properties/level",
"op": "unobserveproperty",
"subprotocol": "sse"
}
]
}
},
"actions": {
"fade": {
"title": "Fade",
"description": "Fade the lamp to a given level",
"synchronous": false,
"input": {
"type": "object",
"properties": {
"level": {
"title": "Brightness",
"type": "integer",
"minimum": 0,
"maximum": 100,
"unit": "percent"
},
"duration": {
"title": "Duration",
"type": "integer",
"minimum": 0,
"unit": "milliseconds"
}
}
},
"output": {
"type": "object",
"properties": {
"state": {
"type": "string",
"emum": ["pending", "running", "completed", "failed"]
},
"output": {
"type": "boolean"
},
"error": {
"$ref": "#/schemaDefinitions/error"
},
"href": {
"type": "string",
"format": "uri"
},
"timeRequested": {
"type": "string",
"format": "date-time"
},
"timeEnded": {
"type": "string",
"format": "date-time"
}
}
},
"uriVariables": {
"actionID": {
"type": "string"
}
},
"forms": [
{
"href": "actions/fade",
"op": "invokeaction",
"response": {
"htv:statusCodeNumber": 201,
"htv:headers": [
{
"@type": "htv:ResponseHeader",
"htv:fieldName": "Location",
"htv:fieldValue": "{actionID}"
}
]
},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "{actionID}",
"op": "queryaction",
"htv:methodName": "GET",
"response": {"htv:statusCodeNumber": 200},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "{actionID}",
"op": "cancelaction",
"htv:methodName": "DELETE",
"response": {"htv:statusCodeNumber": 204},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
}
]
}
},
"events": {
"overheated": {
"title": "Overheated",
"data": {
"type": "number",
"unit": "degree celsius"
},
"description": "The lamp has exceeded its safe operating temperature",
"forms": [
{
"href": "events/overheated",
"op": "subscribeevent",
"subprotocol": "sse",
"htv:methodName": "GET",
"htv:headers": [
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Accept",
"htv:fieldValue": "text/event-stream"
},
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Connection",
"htv:fieldValue": "keep-alive"
}
],
"response": {
"htv:statusCodeNumber": 200,
"htv:headers": [
{
"@type": "htv:ResponseHeader",
"htv:fieldName": "Content-Type",
"htv:fieldValue": "text/event-stream"
}
]
},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"href": "events/overheated",
"op": "unsubscribeevent",
"subprotocol": "sse"
}
]
}
},
"forms": [
{
"op": "readallproperties",
"href": "properties",
"response": {"htv:statusCodeNumber": 200},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"op": "writemultipleproperties",
"href": "properties",
"response": {"htv:statusCodeNumber": 204},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"op": "observeallproperties",
"href": "properties",
"subprotocol": "sse",
"htv:methodName": "GET",
"htv:headers": [
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Accept",
"htv:fieldValue": "text/event-stream"
},
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Connection",
"htv:fieldValue": "keep-alive"
}
],
"response": {
"htv:statusCodeNumber": 200,
"htv:headers": [
{
"@type": "htv:ResponseHeader",
"htv:fieldName": "Content-Type",
"htv:fieldValue": "text/event-stream"
}
]
},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"op": "unobserveallproperties",
"href": "properties",
"subprotocol": "sse"
},
{
"op": "queryallactions",
"href": "actions",
"htv:methodName": "GET",
"additionalResponses": [
{
"success": "true",
"htv:statusCodeNumber": 200,
"schema": "actionStatuses"
},
{
"success": false,
"schema": "error"
}
]
},
{
"op": "subscribeallevents",
"href": "events",
"subprotocol": "sse",
"htv:methodName": "GET",
"htv:headers": [
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Accept",
"htv:fieldValue": "text/event-stream"
},
{
"@type": "htv:RequestHeader",
"htv:fieldName": "Connection",
"htv:fieldValue": "keep-alive"
}
],
"response": {
"htv:statusCodeNumber": 200,
"htv:headers": [
{
"@type": "htv:ResponseHeader",
"htv:fieldName": "Content-Type",
"htv:fieldValue": "text/event-stream"
}
]
},
"additionalResponses": [
{
"success": false,
"schema": "error"
}
]
},
{
"op": "unsubscribeallevents",
"href": "properties",
"subprotocol": "sse"
}
]
}We had ended up with essentially two different ways of using the Web of Things:
- A descriptive approach for brownfield devices using Binding Templates to describe existing IoT protocols
- A prescriptive approach for greenfield implementations using Profiles to provide fixed HTTP-based APIs and out-of-the-box interoperability
This made some amount of sense, but unfortunately the two different approaches didn’t work very well together. A major point of contention was that the prescriptive protocol bindings defined in Profiles could not be fully described using declarative protocol bindings in Thing Descriptions. The descriptive camp blamed the prescriptive camp for trying to extend rather than just constrain Thing Descriptions, and the prescriptive camp blamed the descriptive camp for defining something that wasn’t expressive enough to properly describe the full set of operations.
Bringing the Sides Together
After lots of discussions about how we could reconcile the two different approaches, we eventually came up with an idea of how Profiles and Binding Templates could work together.
The prescriptive protocol binding definitions from Profiles would be moved into binding documents as defaults for protocol bindings, which could be overridden using declarative protocol bindings in forms. Profiles would become simpler and more structured around a fixed set of extension points they could constrain. Rather than defining a protocol binding, a profile would just reference a binding document and mandate that a conformant Thing must stick to its defaults.
This way we would still have the two different approaches, but Profiles would be built on binding documents rather than providing an alternative to them.
It was around this time that some participants from Intel and Oracle (key contributors and supporters of the Profile specification) had to step back from contributing to the Working Group due to redundancies and retirement. However, in 2025 I managed to secure some grant funding to work one day per week on W3C standardisation work, with the following goals:
- Publish a first draft of the Web Thing Protocol WebSocket sub-protocol (which it was agreed was needed regardless of Profiles)
- Polish and publish WoT Profiles 1.0 as a Working Group Note, with a view to discontinuing that work but keeping it as a point of reference.
- Publish a Use Cases & Requirements document for WoT Profiles 2.0, setting out the new proposed approach for the next charter period.
The Web Thing Protocol Community Group succeeded in publishing the first draft of the Web Thing Protocol WebSocket sub-protocol.

I took over leading the Profiles task force and we spent a lot of time polishing the WoT Profile 1.0 working draft (now renamed to WoT Profiles), but a change in W3C process meant that we weren’t allowed to publish it as a Working Group Note and had to just publish a new Working Draft instead.

The Profiles task force wrote a Use Cases & Requirements document for WoT Profiles 2.0 formalising the new proposed approach to Profiles.

This all seemed to be going quite well…
Changing of the Guard
With participants from Oracle and Intel stepping back from the WoT Working Group, the balance of power in the Working Group shifted significantly towards Siemens. The Siemens employees who had written the early position papers at the first W3C WoT Workshop were no longer involved, and the current set of contributors were focused on a very specific set of use cases relating to the onboarding of IoT devices using a range of different protocols to Siemens’ industrial IoT platforms.
Meanwhile, the OPC Foundation published an OPC UA Binding for Web of Things and Microsoft started to adopt WoT Thing Models as a replacement for their own DTDL language in their Azure IoT Operations platform using their own protocol over MQTT.
With the charter of the Working Group soon due for renewal the Chairs of the Working Group were mindful that the overall level of participation in Working Group meetings (of which there were around seven per week across all task forces!) had fallen, and it may be necessary to streamline the growing list of deliverables.
Siemens effectively blocked the publication of the WoT Profiles 2.0 Use Cases & Requirements document as a Working Group Note, and shared the opinion that WoT Profiles should be removed from the list of deliverables for the next charter period (ostensibly delayed, along with WoT Discovery, until the next charter in 2+ years time). They pointed out that the member organisations (particularly Oracle and Intel) who had previously been driving the work on Profiles had now stopped contributing, and unless multiple member organisations stepped forward in support, they would be unable to justify its presence in the charter to the W3C Advisory Committee who need to approve it.
I should explain at this point that the W3C is a paid membership organisation. Member organisations have to pay significant fees in order to participate in standards track activities, and these fees are out of the reach of small startup businesses like mine. After being laid off from Mozilla I had graciously been invited to continue participating in the WoT Working Group (and Web Applications Working Group) as an individual Invited Expert instead, for which there are no fees.
The Invited Expert programme is something I really value and is an important way of getting a more diverse set of people contributing to standardisation at the W3C. However, Invited Experts do not quite have the same set of rights as paid up member organisations, and the reality is their opinions therefore don’t always count for as much. Whilst there were multiple Invited Experts still in support of WoT Profiles, it lacked member organisations willing to commit to active participation.
At the time of writing, the next charter is still being drafted, but the most likely outcome currently seems to be:
- WoT Profiles will be removed as a deliverable from the W3C WoT Working Group charter.
- The WoT Profiles 1.0 specification will never be published as a W3C Recommendation and may eventually have to be published as a Discontinued Draft, which nobody will want to implement.
- The WoT Profiles 2.0 specification will never be written.
How is the Web of Things being used today?
Let’s take a step back from the politics of W3C standardisation for a moment to look at a few practical examples of how the “Web of Things” is actually being used today. For the purposes of this exercise I am going to put aside how we are using the Web of Things at Krellian and the WebThings open source project, and instead look at how other people are using it.
Matter & WoT at Deutsche Telekom
This first example presented at a W3C WoT Community Group Meetup is a project by Till Langen at Deutsche Telekom to integrate the Matter protocol into the Magenta Zuhause platform, using the Web of Things as an abstraction. Matter is a popular smart home protocol that has been adopted by big tech companies like Apple, Google and Amazon.
First Till describes a design concept he worked on as part of his Bachelor thesis for integrating Matter by directly describing the Matter protocol using Thing Descriptions. Due to the hierarchical nature of how a physical device is modelled in Matter, Till found the easiest way was to create a Thing Description for each Matter “endpoint”. This means that a single physical device is actually described by a collection of Thing Descriptions, with link relations describing the relationships between them.
The Matter concepts of attributes, commands and events map quite neatly onto the WoT concepts of properties, actions and events. However, whilst the Matter protocol technically does have a URI scheme, mt:, URIs only contain information like vendor ID, product ID and some other parameters that help with the onboarding process, they are not used for identifying individual resources. This meant that in order to directly describe Matter operations using hypermedia forms in Thing Descriptions Till had to invent his own theoretical matter:// URI scheme.
So for example:
- A URI for carrying out a read property operation has the form
matter://<node_id>/<endpoint_id>/<cluster_name>/read/<attribute_name> - A URI for carrying out an invoke operation has the form
matter://<node_id>/<endpoint_id>/<cluster_name>/invoke/<command_name>?<parameterX>=<value> - A URI for subscribing to an event has the form
matter://<node_id>/<endpoint_id>/<cluster_name>/subscribe/<event_name>?<parameterX>=<value>
Whilst a clever way of embedding all the information needed to carry out an operation in a URI, you can see that these URIs are not very RESTful (e.g. using verbs like “read”, “invoke” and “subscribe” in the URIs). This is because the Matter protocol is not inherently resource-oriented or RESTful, so trying to serialise operations as hypermedia forms is not a natural fit. You’ll see that this approach of trying to retrofit a contrived URI scheme onto a protocol which is not inherently resource oriented will become a bit of a common theme.
The theoretical Matter binding also defines semantic ontologies for describing a range of Matter-specific concepts including a custom security scheme called mattersecurity:SecurityScheme, semantic types for affordances like matter0x0006:0x02 and custom link relation names like matterDescriptorCluster:0x0003.
I think it’s also important to note that whilst Matter is technically an internet protocol (it’s based on IPv6), in practice it is almost exclusively used on local networks rather than being directly exposed to the internet.
Later in the presentation Till goes on to explain that the proof of concept implementation he worked on did not actually use this matter:// URI scheme at all, but instead bridged Matter to the HTTP protocol using a much more RESTful approach that also works well over the internet and is easier for apps to consume.
Creating an abstraction on top of Matter for apps to consume is not unusual. In fact end user applications rarely speak the Matter protocol directly, but use an abstraction like Apple’s HomeKit, Google’s Home API on Android and Home Graph in the cloud, and Amazon’s Smart Home Skills API for Alexa.
OPC UA & WoT at the OPC Foundation
OPC UA is an IEC standard for data exchange mostly used in industrial IoT and sometimes commercial buildings. The OPC UA standard is intended to be protocol agnostic, but the most commonly used protocol mapping is a binary format over TCP. There are also mappings for UDP/IP, WebSockets, AMQL and MQTT.
In this WoT Community Group meetup, Erich Barnstedt from Microsoft and Sebastian Käbisch from Siemens (also co-chair of the W3C WoT Working Group) describe their work with the OPC Foundation to use OPC UA with the Web of Things via companion specifications.
Erich set out to try to make industrial assets more discoverable using WoT Thing Descriptions. He describes a project which uses the GPT4 large language model to automatically generate Thing Descriptions for assets in order to map them to the OPC UA information model. He gives examples of describing devices using WoT Thing Descriptions, with Forms using URIs with a modbus:// URI scheme, and adding Modbus and OPC UA specific semantic annotations. The modbus:// URI scheme is not formally registered with IANA, and whilst some Modbus devices use an IP transport others actually use a serial connection and a WoT Consumer would not be able to distinguish between the two.
Erich mentions the OPC WoT Connectivity specification which describes an OPC UA specific API for managing assets and uploading a WoT Thing Description, and the UA Edge Translator open source project which bridges a range of proprietary industrial protocols to OPC UA. I think it’s important to note that here is a project which is using WoT Thing Descriptions to map non-web protocols to another non-web protocol. The web as we traditionally understand it is not actually involved at all, and yet it is described under the banner of the “Web of Things”.
Sebastian then goes on to introduce another OPC UA companion specification he worked on with Erich – the OPC UA WoT Binding. He explains that while OPC UA has an existing solution for describing devices using XML, it is very complex and requires a deep understanding of the protocol. The OPC UA WoT Binding makes it possible to expose a small subset of the functionality of OPC UA using a WoT Thing Description, which makes it easier for a range of IoT applications to consume.
To make it possible to describe OPC UA directly using a WoT Thing Description, the OPC UA WoT Binding defines a URI scheme for OPC UA (again, is not formally registered with IANA), with the following format:
opc.tcp://<address>:<port>[/<resourcePath>]/?id=<nodeId>Whilst OPC UA’s information model is object and reference-centric with a graph of nodes which may feel kind of resource-oriented, the OPC UA protocol was primarily designed as a connection-oriented, stateful industrial protocol and is not inherently resource-oriented or RESTful. OPC UA over TCP uses its own binary protocol with long-lived sessions and a rich set of services (e.g. browser, read, write, call methods, subscribe etc.), rather than the constrained HTTP verbs of REST. This means that trying to describe operations using hypermedia forms is not a natural fit.
The OPC UA WoT Binding manages to squeeze the important information needed to carry out operations on an OPC UA device into a URI, but there is also an optional semantic ontology for annotating a Thing Description with OPC UA specific concepts with terms like uav:object, uav:variable, uav:method, uav:hasComponent and uav:componentOf. Whilst these annotations are optional, this is another example of protocol specific terms creeping into the Thing Description, which is being used to directly describe an existing protocol rather than providing a web abstraction on top of it.
Next Sebastian gives some examples of what he describes as the benefit of giving devices Thing Descriptions, using the WoT Scripting API implemented in the Eclipse Thingweb (node-wot) open source project. Below is an example he gives of a script which consumes devices using both OPC UA and HTTP, without worrying about protocol specific concepts like nodeID, HTTP methods, contentType etc.
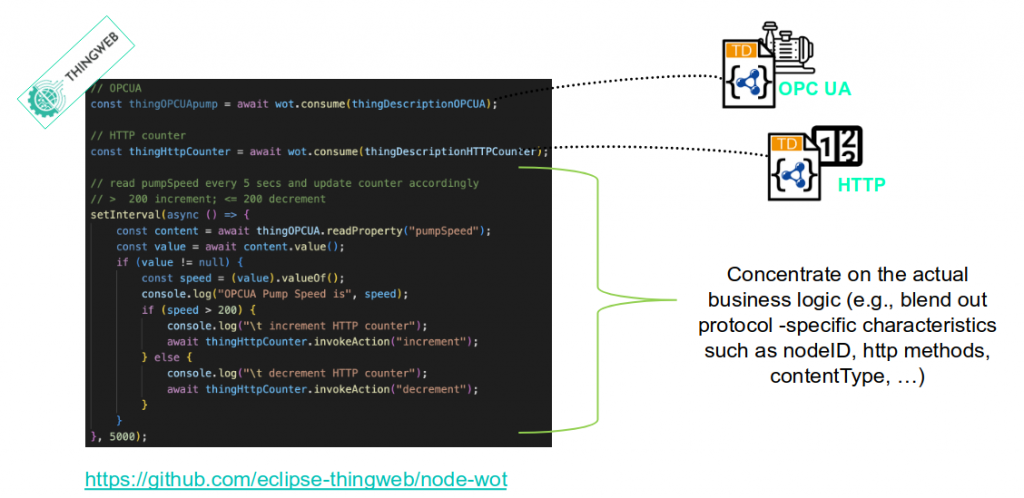
These examples really made something click for me. When consuming different protocols using node-wot it is the scripting API which appears to be the “narrow waist” of the Web of Things. This is where the abstraction happens and all of the protocol-specific concepts fall away. Suddenly it made sense to me why people working with node-wot don’t see protocol bindings as a problem, but as the solution – because the bindings are entirely hidden from developers writing application code.
The problem with this approach for me is that whilst you may be able to write an application in JavaScript (specifically JavaScript, which is what the Scripting API is designed for) which doesn’t have to worry about protocol specifics, fundamentally every WoT Consumer implementation still has to implement potentially dozens of individual protocols in order to interoperate. This is not web-style interoperability, as I will discuss further below.
Interestingly, after attending this meetup I discovered that OPC UA now has its own Web API and WebSocket sub-protocol – which do expose devices directly to the web using HTTP and WebSockets, but they are not used here.
BACnet & WoT at Siemens
The next example is from a WoT Community Group presentation by Doğan Fennibay at Siemens.
Doğan explains that a typical complex commercial building may have systems which use a range of protocols like KNX, M-bus, Modbus and BACnet. Siemens has the Desigo CC building management platform on the edge, and Building X platform in the cloud, which help to bridge all of these systems together. He says that whilst BACnet is very popular and has a 77% market share in buildings, an increasing number of IoT developers creating edge and cloud applications like to have a web-like paradigm to interact with. There are also specific verticals like integration into the energy grid which BACnet does not currently support.
Doğan notes the trend towards using IP everywhere, including IPv6 replacing serial protocols, and that WoT is well placed to extend BACnet to help complete these integrations.
BACnet is an ISO/ASHRAE/ANSI standard protocol for building automation and control systems like HVAC, lighting, access, control, fire alarms, meters and sensors. It models devices as collections of “objects” using 60 object types (e.g. Analog Input, Binary Output, Schedule, and Trend Log) that are acted upon by “services”. The standard (which you have to pay for a copy of if you want to read it) defines a number of transports including ARCNet, Ethernet, IP, MSTP, RS-232 and even Zigbee – but IP and MS/TP dominate today. BACnet over IP uses binary messages with a compact TLV-style (tag, length, value) structure encapsulated in UDP packets.
Doğan then goes on to introduce the WoT BACnet Binding – a draft specification that aims to directly describe BACnet devices using WoT Thing Descriptions. He emphasises that the binding takes a use case driven approach to only describing a small subset of BACnet features (he notes that the bacowl ontology contains 17,601 triples alone!).
The BACnet binding re-uses and extends the bacnet:// URI scheme defined in BACnet specifications (which again is not yet formally registered with IANA), an example of which is shown below.
bacnet://5/0,1/85
This URI scheme represents a device ID, object ID and optional property ID. The WoT Binding extends this URI scheme with the URI variables commandPriority, relinquish and covIncrement to provide further information. The binding also defines a vocabulary for annotating a Thing Description with additional BACnet-specific details such as bacv:usesService, bacv:isISO8601 and bacv:hasBinaryRepresentation. It maps BACnet objects (not properties) to WoT properties, notification classes to events, and uses action affordances for things like synchronisation. BACnet only supports one encoding format based on ASN.1, but since there is no specific IANA registered MIME type for that, the binding enforces that application/octet-stream should always be used.
The BACnet protocol is kind of resource-oriented if you squint, but it’s certainly not RESTful, and the vocabulary defined in the binding surfaces a lot of BACnet-specific concepts in Thing Descriptions.
When asked, Doğan says he sees the WoT information model (properties, actions and events) as being the narrow waist of the Web of Things. There are protocol specifics in Thing Descriptions, but the data model is common.
After the meetup I discovered that BACnet actually has a standardised REST API called BACnet/WS which was defined in the ASHRAE 135-2024 release, but that isn’t used here.
MQTT & WoT at Microsoft
The final example is a potentially quite exciting usage by Microsoft, which had been alluded to in some WoT Working Group meetings, but has finally been revealed in a GitHub repository. The headline is that the Azure IoT team are working on replacing their own DTDL language for describing digital twins with W3C WoT Thing Models in their Azure IoT Operations platform.
On the surface this seems like a huge win for the Web of Things, but when you dig down into the details you will see that rather than creating web things that any existing WoT Consumer would be able to consume, the AIO team are creating a vendor-specific AIO binding to describe their own AIO protocol over MQTT.
The W3C Working Group has an existing draft of a WoT MQTT binding, but Microsoft’s implementation does not use it. The README in the GitHub repository explains why they made this decision, but essentially whilst AIO is built on an MQTT transport, the specific dialect it speaks to perform operations (topic patterns, a JSON-based RPC “state store” protocol, and CloudEvents wrapper for telemetry events etc.) is vendor-specific. Presumably this could not all be fully described using existing binding vocabularies.
This means that in order to consume these web things, WoT Consumers would first need to implement this Azure-specific WoT ontology (including 17 custom RDF terms like aov:capability, aov:component and aov:reference) in order to parse Thing Descriptions, and then implement an Azure-specific protocol to communicate with the Things. This is not really how WoT bindings were intended to be used, and whilst I understand why they did it (they had an existing platform they wanted to describe), unfortunately the resulting implementation has a bit of an embrace, extend and extinguish flavour to it.
As you can probably guess by now, it appears that Azure IoT Operations also has its own HTTP REST API (although it is primarily designed for getting data into the system rather than out of it).
What’s Not Working
There are countless more examples I could give of how the Web of Things is being used today, many of which are implementing the Web of Things using web protocols like the WebThings project does, but I hope these examples are sufficient to get my point across.
That point is that we started out by creating a tool for describing level 3 maturity REST APIs using hypermedia controls, and then over time tried to use it for describing a bunch of IoT protocols which in most cases are not even level 0. The Working Group tried to make this work by retrofitting URI schemes to existing protocols, but unfortunately contriving a URI scheme for a connection-oriented stateful protocol doesn’t make it resource-oriented or stateless.
At times this has inevitably led people to ask whether the strict constraint of requiring protocols to have URI schemes should just be dropped, and Thing Descriptions should be free to use other ways of describing communication interfaces. I strongly reject that idea, because if URLs are removed from the Web of Things then there’s really no “web” left at all, and it’s just another IoT metadata format.
However, because existing IoT protocols are not a natural fit for hypermedia forms, describing them directly in Thing Descriptions requires extending the WoT information model using complex semantic ontologies. These ontologies then surface a lot of protocol specifics in Thing Descriptions, which Consumers have to parse and understand. Whilst this declarative mechanism may work for simple examples and one-off single-vendor integrations, I still haven’t seen much evidence that it can really provide the kind of cross-vendor plug-and-play interoperability we have come to expect from the web. There are always cases when a Thing Description is not expressive enough and unambiguous enough to describe a given protocol and payload binding to the extent that a Consumer can understand what to do without additional out-of-band knowledge.
What is also clear is that in all of the above examples we know it would be possible to bridge the protocols to an HTTP-based REST API if we wanted to, because it has already been done!
I want to be clear that it is not my intention to criticise implementers like Deutsche Telekom, Siemens and Microsoft here for “doing WoT wrong”. They have specific use cases they are trying to solve like onboarding industrial IoT devices and bridging smart home protocols to their own platforms. (Siemens in particular deserve a huge amount of credit for pushing the Web of Things forward.) If the existing WoT specifications are solving those use cases for them then that’s great, I don’t think there’s anything wrong with that. Even just defining a common metadata format for IoT is useful.
What I think is missing is the bigger picture thinking about what a Web of Things was originally envisioned to be and what makes it the Web of Things as opposed to the Internet of Things. Rather than lots of isolated networks of things using different protocols, how we can achieve a universal Web of Things on the scale of the World Wide Web which is greater than the sum of its IoT parts?
What is the narrow waist of the Web of Things?
After attending a lot of WoT Community Group meetups like the ones above, I started asking people a question. What do you think is the “narrow waist” of the Web of Things? I’ve used that term a few times now so let me just explain what it means.
This term comes from the hourglass model of computer networking, for describing “a layered system design in which a single, widely adopted spanning layer sits at the narrow “waist” of the stack and serves as the sole common interface between many heterogeneous lower-layer technologies and many diverse higher-layer applications.” In the context of the wider internet, the Internet Protocol (IP) is traditionally considered this spanning layer.
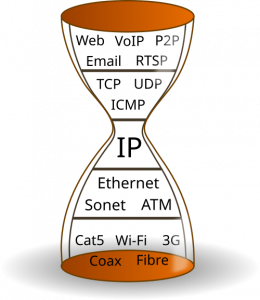
When I ask this question about the Web of Things, which also has a layered system design, the most common answers I get are:
- WoT Scripting API – since it allows the same application logic to be used across different protocols
- WoT Information Model – the common abstraction in Thing Descriptions for describing capabilities of devices across different protocols
Neither of these answers feel satisfying to me, because in both cases it means that WoT Consumers (like apps, services and intelligent agents) still ultimately have to implement potentially dozens of underlying IoT protocols in order to communicate with the full range of devices. Whilst it might help slightly with onboarding or scripting, it doesn’t really effectively “counter the fragmentation of the IoT” as per the stated mission of the W3C Web of Things. It doesn’t provide web-style interoperability.
I recently read the book This is for Everyone by Tim Berners-Lee, the inventor of the World Wide Web. Along with his previous book, Weaving the Web, the book charts the history of the invention and evolution of the web, the problems he set out to solve, and how the web came to be what it is today (including the design issues he now sees, and how he proposes to fix them).

This is a great book which I really recommend reading, but in the book Tim is very clear about the important components that made up his invention – URLs, HTTP and HTML.
To look at web development today you could be forgiven for thinking that the JavaScript runtime in the browser is the “narrow waist” of the Web, which enables web applications to run on browsers from different vendors, and to a small extent that is true. However, what enabled the World Wide Web to grow in the first place was not JavaScript (which didn’t even exist in the first web browsers), but HTML, HTTP and URLs. Whilst JavaScript provides an important layer of client-side application logic on top, what really defines the web is that it is a global network of resources linked together by URLs, whose value comes just as much from the links representing relationships between the resources as it does from the content of the resources themselves.
If the web had started as a JavaScript (or probably Mocha or LiveScript back then) runtime which had a consistent data model and scripting API, but all the web pages had to be retrieved using different protocols and parsed from different data formats (instead of predominantly HTTP and HTML), I simply don’t believe that it would have got off the ground in the first place. There were certainly other hypertext protocols competing with HTTP in the early days of the web, but it didn’t start to really take off until we settled on one. The narrow waist of the web is HTTP (and URLs).
This is important, because if we genuinely want to learn lessons from how the World Wide Web transformed the Internet and apply them to the Internet of Things, we need understand what made it unique.
So what is the narrow waist of the Web of Things? I don’t think it’s the Scripting API. I don’t think it’s the information model. I think the narrow waist of the Web of Things is missing.
The Web Thing Protocol
Enter the Web Thing Protocol – a common protocol for communicating with connected devices over the web. Not just the WebSocket sub-protocol which has been defined so far (which itself is not particularly resource-oriented or RESTful), but a dedicated HTTP-based application layer protocol for the Web of Things as originally set out in the Web Thing Protocol Use Cases & Requirements report.
Going back to the original vision from Building the Web of Things and the original Web of Things community. Going back to the clear early consensus from the very first W3C Workshop on the Web of Things. Going back to the proposed approach from EVRYTHNG’s Web Thing Model and Mozilla’s Web Thing API. Choosing not to limit the Web of Things to simply describing the existing fragmented IoT landscape, but reaching for something more universal.
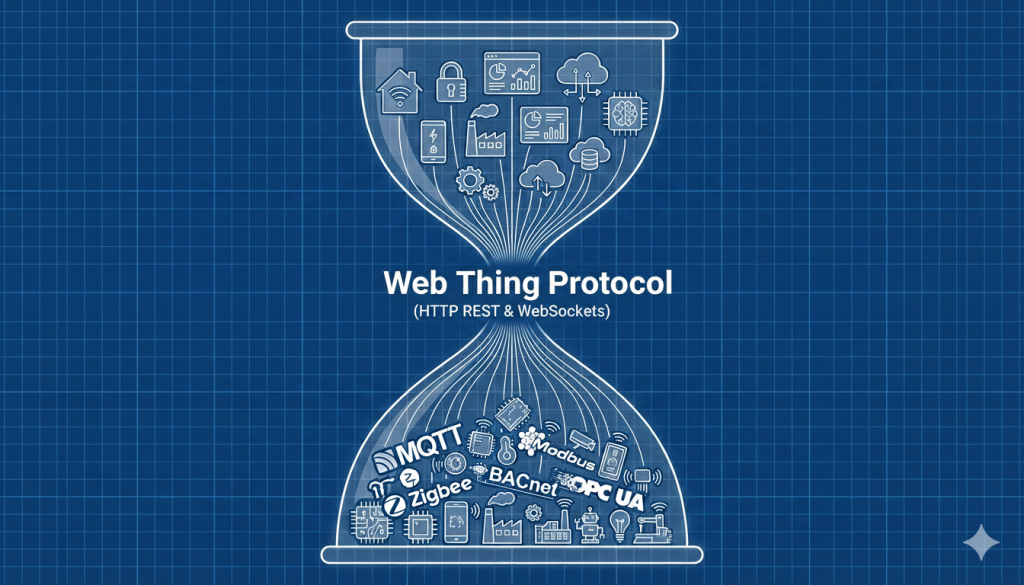
Rather than trying to design a JSON-based metadata format which is theoretically capable of describing the minute details of individual operations in any protocol and payload format, I propose that the Web of Things should instead provide a prescriptive universal web-based abstraction on top of those protocols. Thing Descriptions should hide rather than expose protocol and platform-specific concepts, and instead represent Things using collections of resources with URLs (with real IANA-registered URI schemes and MIME types), and a prescriptive RESTful API using the basic set of HTTP verbs (extended with Server-Sent events for push notifications, and WebSockets for efficient real-time communication where necessary).
Semantic annotations can add a rich optional additional layer of meaning on top of Thing Descriptions, using (sometimes domain-specific but always protocol-agnostic) ontologies to explain the information that is being represented, not the protocol or payload format used to transport it. This will result in a truly plug-and-play, domain-agnostic Web of Things where any Consumer can communicate with any Thing on at least a basic level, and Consumer implementations like apps, services and intelligent agents don’t have to implement dozens of different protocols in order to participate.
Although I still think a more structured profiling mechanism could still be useful in the long term, overall I feel that WoT Profiles may have been a distraction that just delayed me from working on the thing that the Mozilla IoT team originally set out to build – a universal application layer protocol for the Internet of Things. I believe that this is the missing waist of the Web of Things, and the key missing piece needed for it to really grow.
The good news is that the work from WoT Profiles will not have been wasted. As a starting point for the Web Thing Protocol HTTP Sub-protocol I have created a strawman proposal which takes the protocol bindings from the HTTP Basic Profile and HTTP SSE Profile and combines them into a single “sub-protocol”.
I’m not sure that “sub-protocol” is exactly the best term for what this is. The WebSocket protocol specification specifically defines the concept of “sub-protocols”, but the HTTP protocol does not. I’m calling it a sub-protocol because it is initially intended to use the sub-protocol mechanism which is already baked into Forms in Thing Descriptions, instead of the profiling mechanism. Below is an example Thing Description for the same web thing described in the profile examples above, but using the sub-protocol mechanism rather than the profiling mechanism:
{
"@context": "https://www.w3.org/2022/wot/td/v1.1",
"id": "https://mywebthingserver.com/things/lamp",
"base": "https://mywebthingserver.com/things/lamp/",
"title": "My Lamp",
"description": "A web connected lamp",
"securityDefinitions": {
"oauth2": {
"scheme": "oauth2",
"flow": "code",
"authorization": "https://mywebthingserver.com/oauth/authorize",
"token": "https://mywebthingserver.com/oauth/token"
}
},
"security": "oauth2",
"properties": {
"on": {
"type": "boolean",
"title": "On/Off",
"description": "Whether the lamp is turned on",
"forms": [
{
"href": "properties/on",
"op": [
"readproperty",
"writeproperty",
"observeproperty",
"unobserveproperty"
],
"subprotocol": "webthingprotocol"
}
]
},
"level" : {
"type": "integer",
"title": "Brightness",
"description": "The level of light from 0-100",
"unit": "percent",
"minimum" : 0,
"maximum" : 100,
"forms": [
{
"href": "properties/level",
"op": [
"readproperty",
"writeproperty",
"observeproperty",
"unobserveproperty"
],
"subprotocol": "webthingprotocol"
}
]
}
},
"actions": {
"fade": {
"title": "Fade",
"description": "Fade the lamp to a given level",
"synchronous": false,
"input": {
"type": "object",
"properties": {
"level": {
"title": "Brightness",
"type": "integer",
"minimum": 0,
"maximum": 100,
"unit": "percent"
},
"duration": {
"title": "Duration",
"type": "integer",
"minimum": 0,
"unit": "milliseconds"
}
}
},
"forms": [
{
"href": "actions/fade",
"op": [
"invokeaction",
"queryaction",
"cancelaction"
],
"subprotocol": "webthingprotocol"
}
]
}
},
"events": {
"overheated": {
"title": "Overheated",
"data": {
"type": "number",
"unit": "degree celsius"
},
"description": "The lamp has exceeded its safe operating temperature",
"forms": [{
"href": "events/overheated",
"op": [
"subscribeevent",
"unsubscribeevent"
],
"subprotocol": "webthingprotocol"
}]
}
},
"forms": [
{
"href": "properties",
"op": [
"readallproperties",
"writemultipleproperties",
"observeallproperties",
"unobserveallproperties"
],
"subprotocol": "webthingprotocol"
},
{
"op": "queryallactions",
"href": "actions",
"subprotocol": "webthingprotocol"
},
{
"op": [
"subscribeallevents",
"unsubscribeallevents"
],
"href": "events",
"subprotocol": "webthingprotocol"
}
]
}A more accurate term than “sub-protocol” might be “domain application protocol” (where the domain is IoT as a whole). But regardless of what you call it, the idea of building an application layer protocol on top of HTTP is certainly not new. Existing successful examples include the Atom Publishing Protocol, ActivityPub, AT Protocol, Matrix, GraphQL, gRPC, the currently very trendy MCP and even Solid – designed by Tim Berners-Lee himself.
Again, I want to emphasise that my argument is not that a protocol built on HTTP is going to be the best IoT protocol, or that all IoT protocols should be replaced with it. There are many reasons that HTTP is poorly suited to IoT, which require it to be extended with mechanisms like Server-Sent Events and (the not so RESTful) WebSockets for certain use cases. My argument is instead that the history of the web suggests that a simple ubiquitous protocol based on a resource-oriented REST architecture can provide a universal abstraction layer on top of a rich tapestry of specialised underlying protocols, that an open ecosystem of apps, services, and intelligent agents can consume. And that this simple abstraction layer could have the potential to unlock an exponential increase in the size and value of the network.
What’s Next?
It appears that for its next charter period the WoT Working Group will be focusing on WoT Thing Description 2.0 as its only normative deliverable, along with the WoT Binding Registry, WoT Scripting API and other supporting documents.
Thing Description 2.0 will bring some welcome optimisations that will be useful for the Web Thing Protocol as well. I suggest that we accept that work on WoT Profiles is at least paused for now, and rather than try to define a comprehensive profiling mechanism which can constrain all of the different extension points of the Web of Things, we narrow our focus to defining a re-usable, prescriptive HTTP protocol binding (the Web Thing Protocol) using the existing sub-protocol mechanism instead.
Whilst the Working Group focuses on the Thing Description specification I propose that the Web Thing Protocol Community Group continues to incubate the Web Thing Protocol specification as a complement to that key building block, working closely with the Working Group to ensure continued alignment.
We should then work on a plan for eventually getting the Web Thing Protocol onto a standards track, either as a deliverable in the next charter of the WoT Working Group, a new dedicated Working Group at the W3C, or alternatively a new Working Group at the IETF.
To be clear, I think the descriptive approach and prescriptive approach can continue to co-exist (as long as it doesn’t result in too much complexity in the core specifications). Time will tell which one of them will allow the Web of Things to truly scale.
Call to Action
What can you do to help?
📄 Firstly, the Web Thing Protocol Community Group needs a diverse set of people to contribute to writing and reviewing the Web Thing Protocol specification, so that it’s the best protocol it can be. With the group’s support I hope we will soon start to work on defining the Web Thing Protocol HTTP sub-protocol, starting from the use cases and requirements we have defined and the strawman proposal I have already shared. We will also continue to work on refining the WebSocket sub-protocol based on implementation feedback. Note that anyone can join the Web Thing Protocol Community Group and contribute on GitHub, you don’t need to be a W3C member.
💡 Secondly, you can help by implementing the Web Thing Protocol in your project, product or service. The WebThings project will need help implementing the Web Thing Protocol in WebThings Gateway, and in a range of different programming languages in the WebThings Framework. There is also the beginnings of a Web Thing Protocol client implementation in node-wot.
In a future blog post I will also write about what I think is a key piece of software that the Web of Things lacks – the equivalent of a browser for the Web of Things. I will explain why I am working on a WebThings app that will act as a general purpose WoT Consumer on desktop and mobile, and how I believe that will help bring the Web of Things to a broader audience.
Let’s put the web back in the Web of Things.
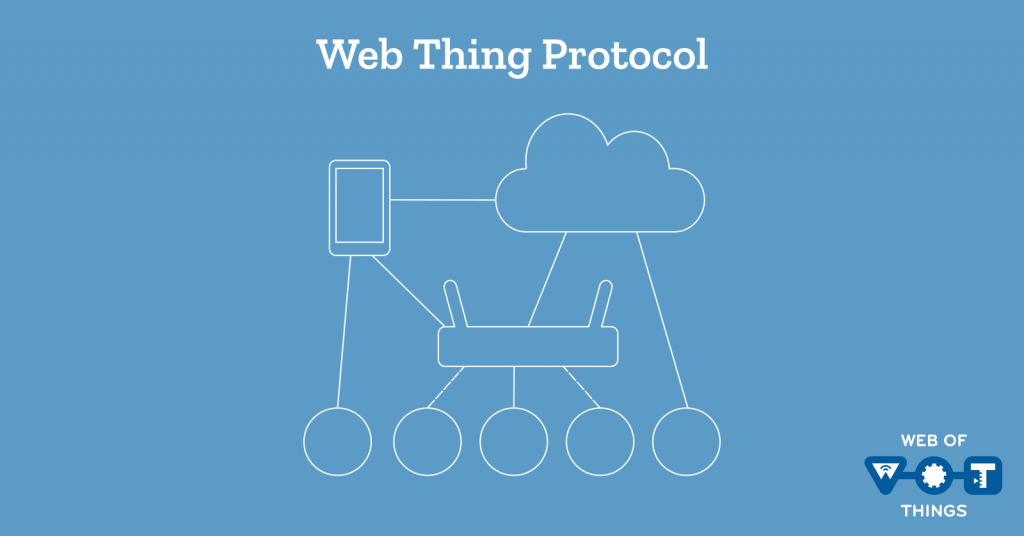
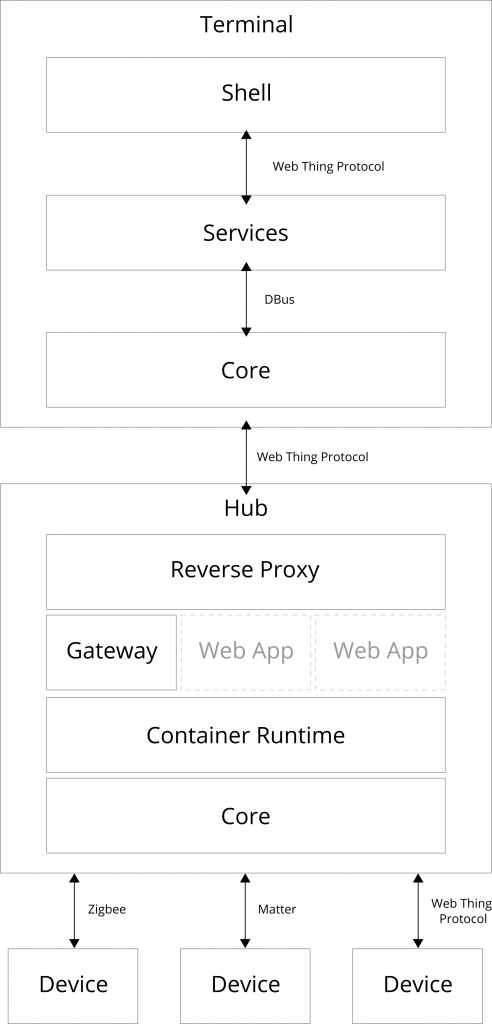



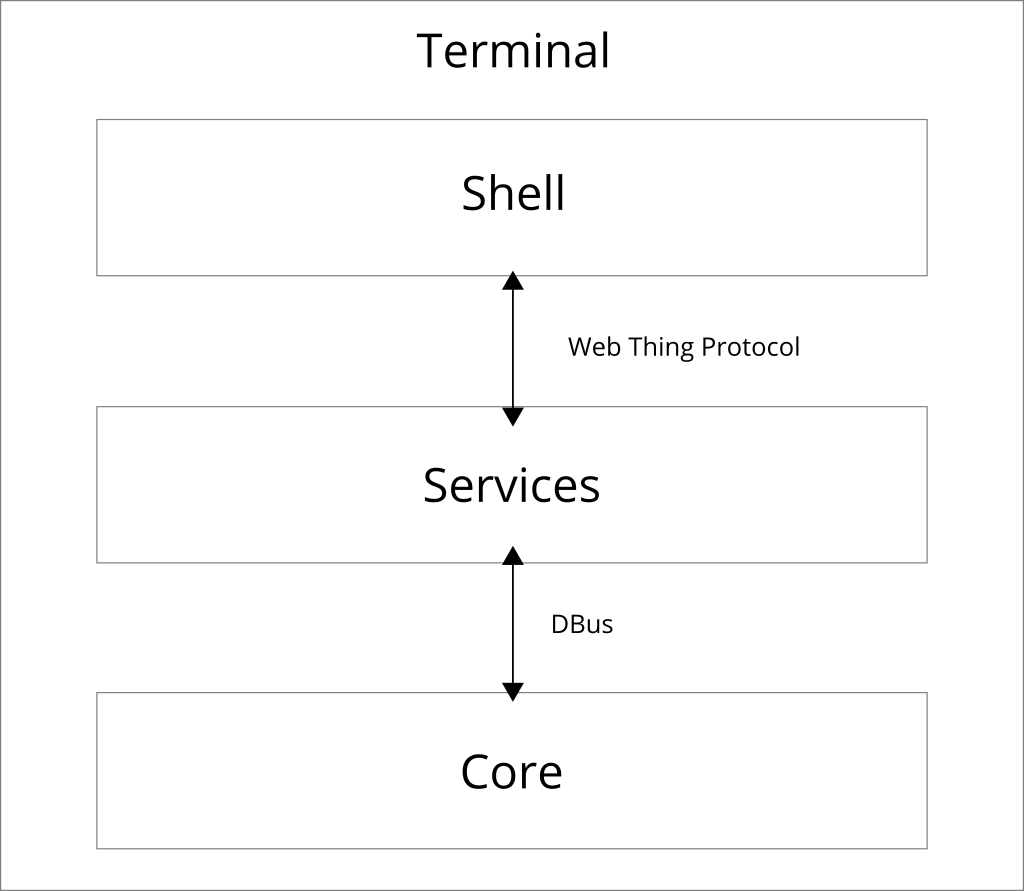





















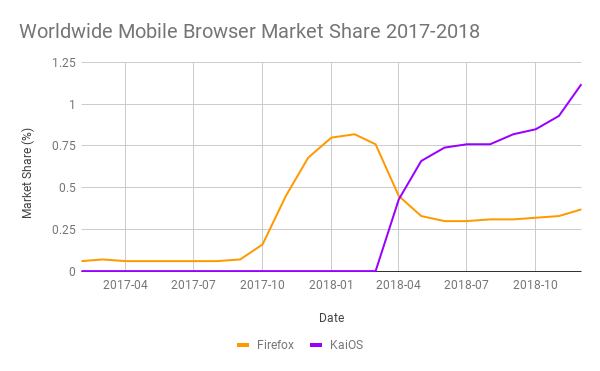
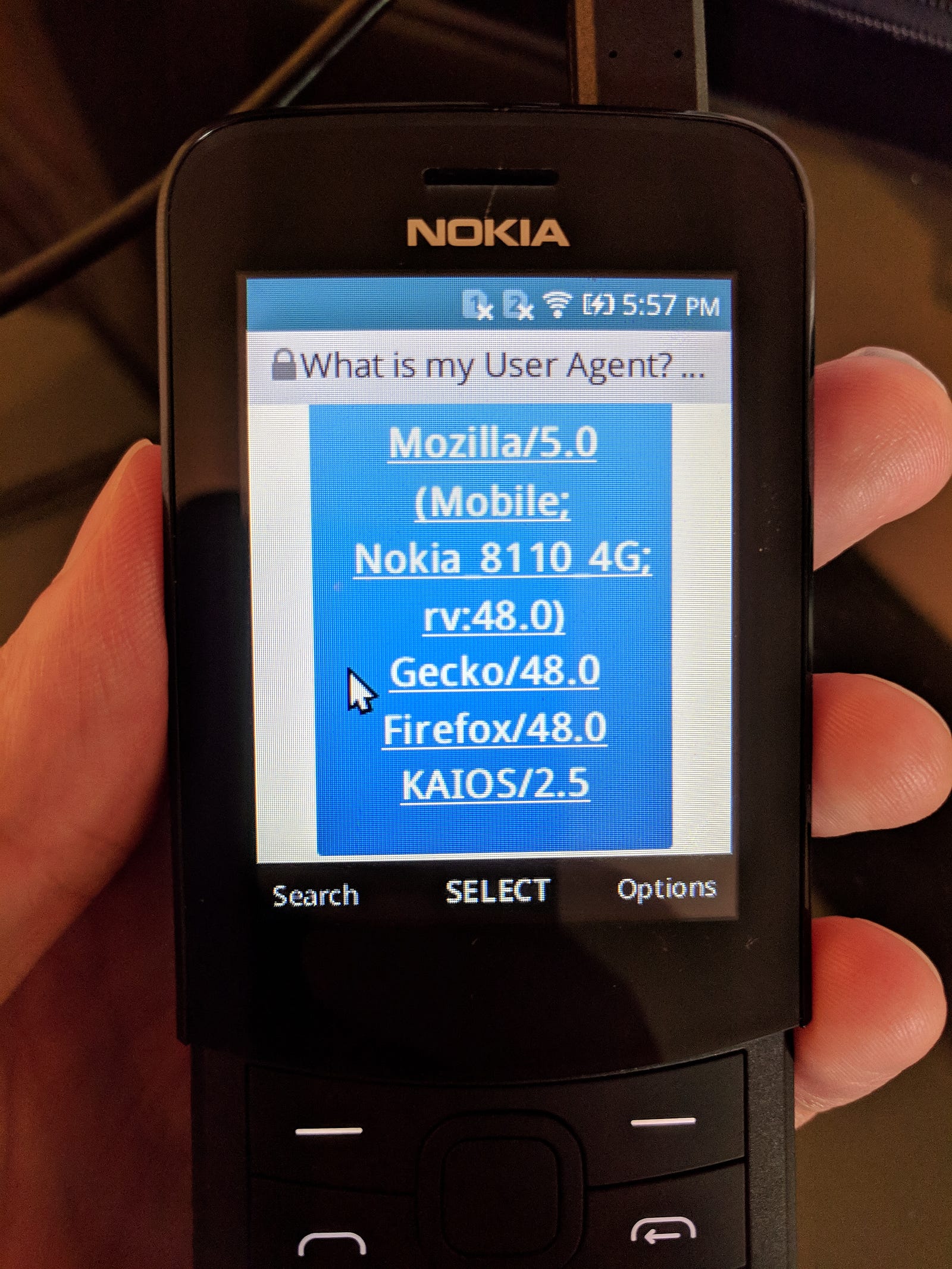





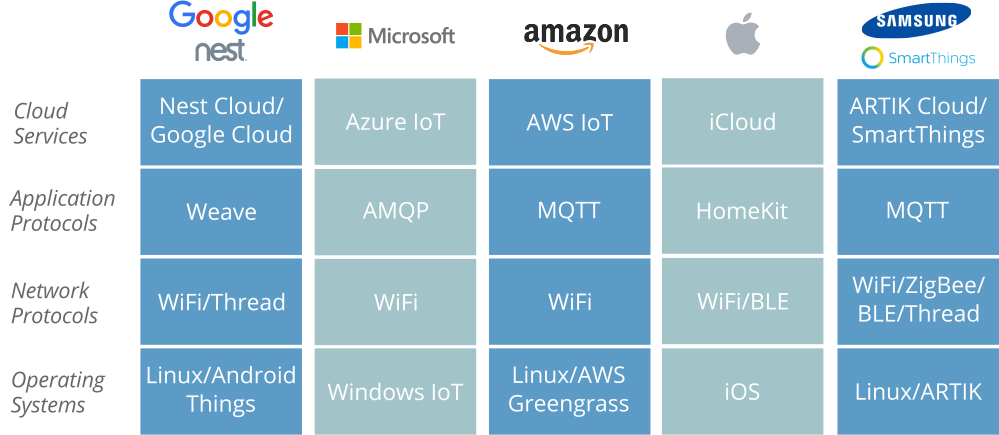
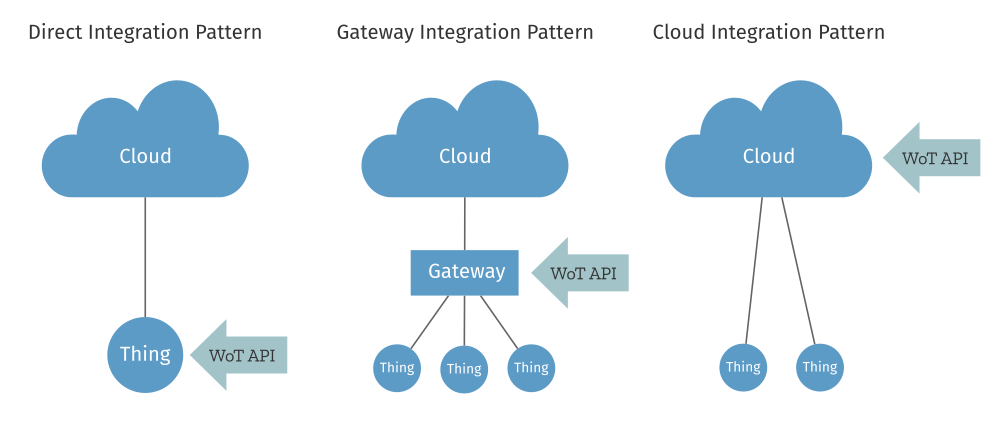
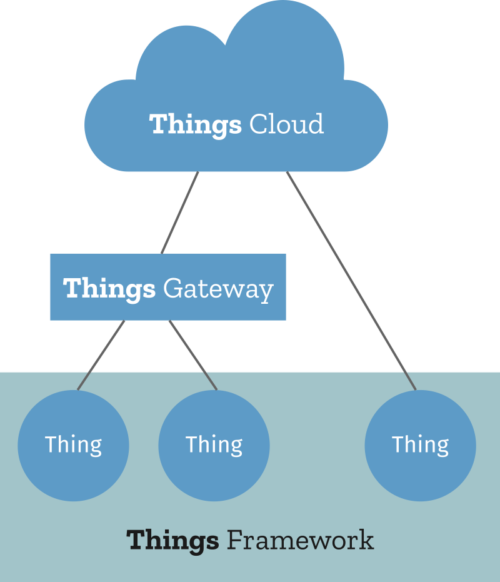
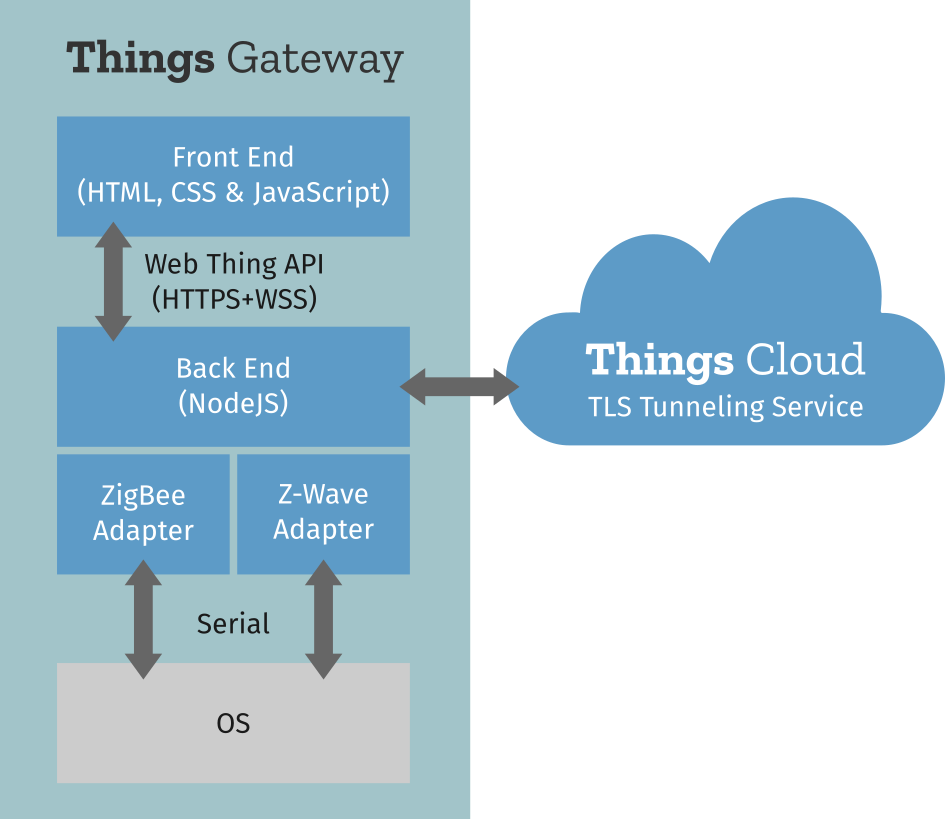
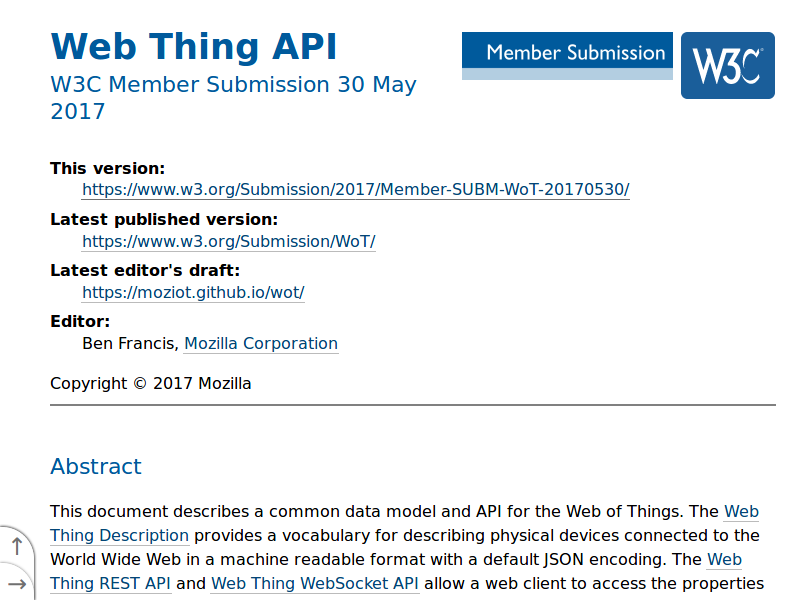























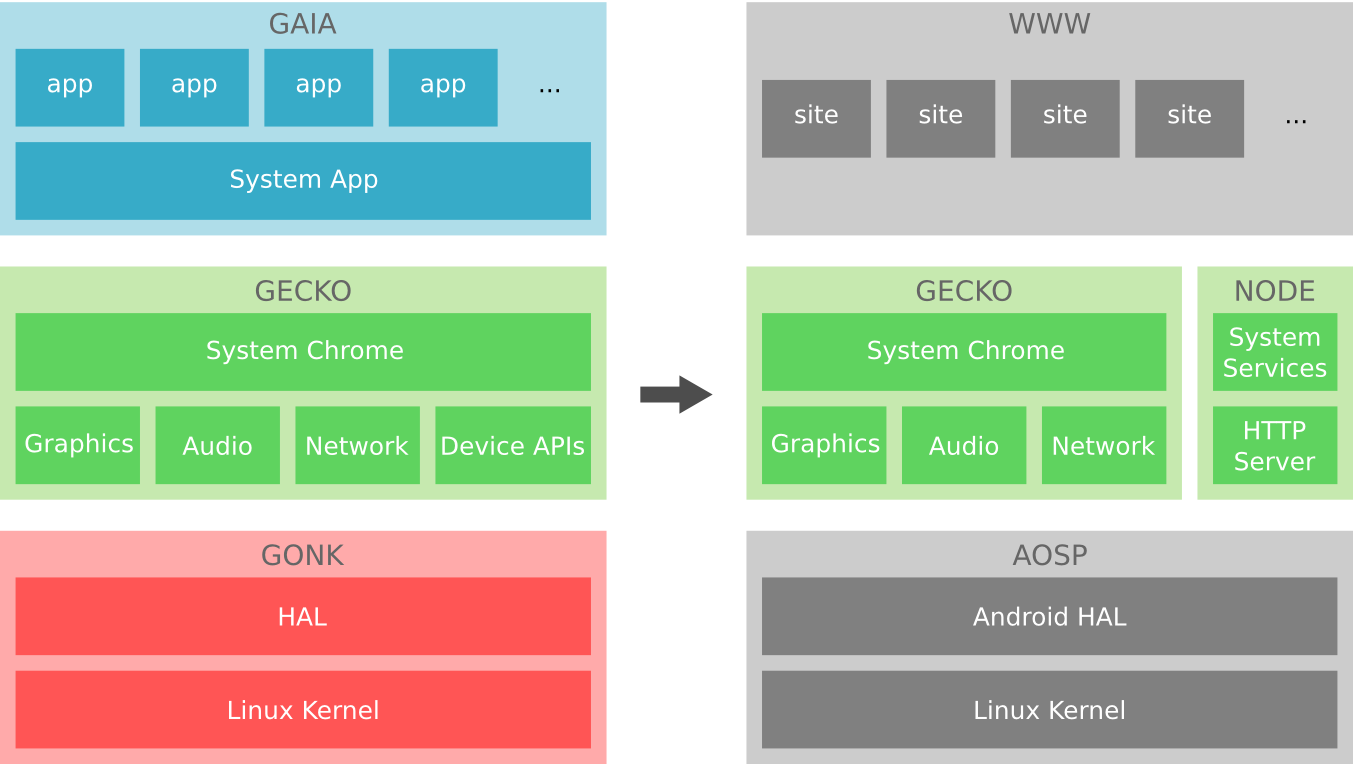









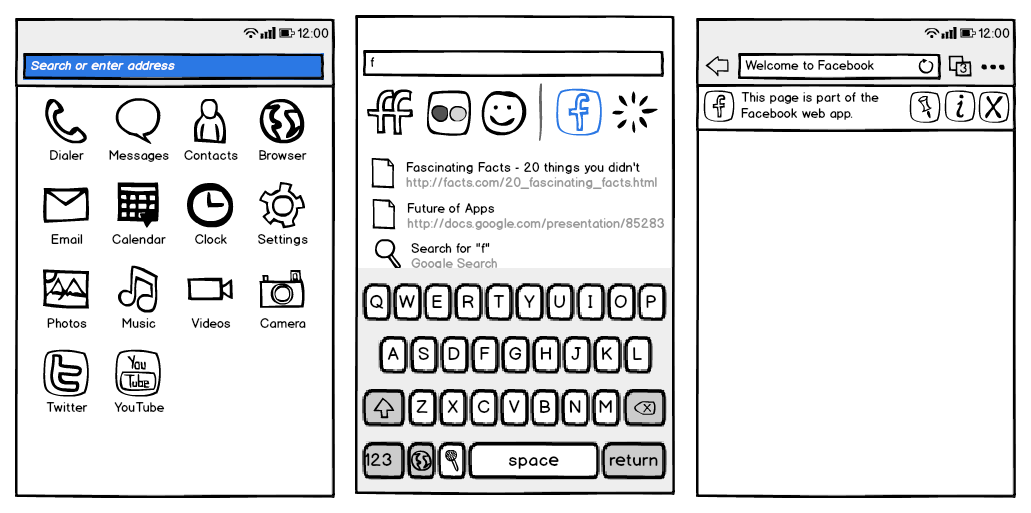

{kind=link}